|
I am a Research Assistant at University of Michigan, where I work on computer vision and deep learning for medical imaging advised by Prof. James Balter. I recently completed my masters in EECS, Computer Vision from University of Michigan where I was fortunate enough to work with Prof. David Fouhey on problems in Robot Navigation/3D visual scene understanding and compete in The Alexa Prize Socialbot Grand Challenge . I also have an undergraduate degree in Mechanical Engineering from IIT Kanpur, India along with a minor in Artificial Intelligence. Email / CV / Google Scholar / LinkedIn |
|
|
My research interests are in computer vision, deep learning, reinforcement learning, and medical imaging. |
|
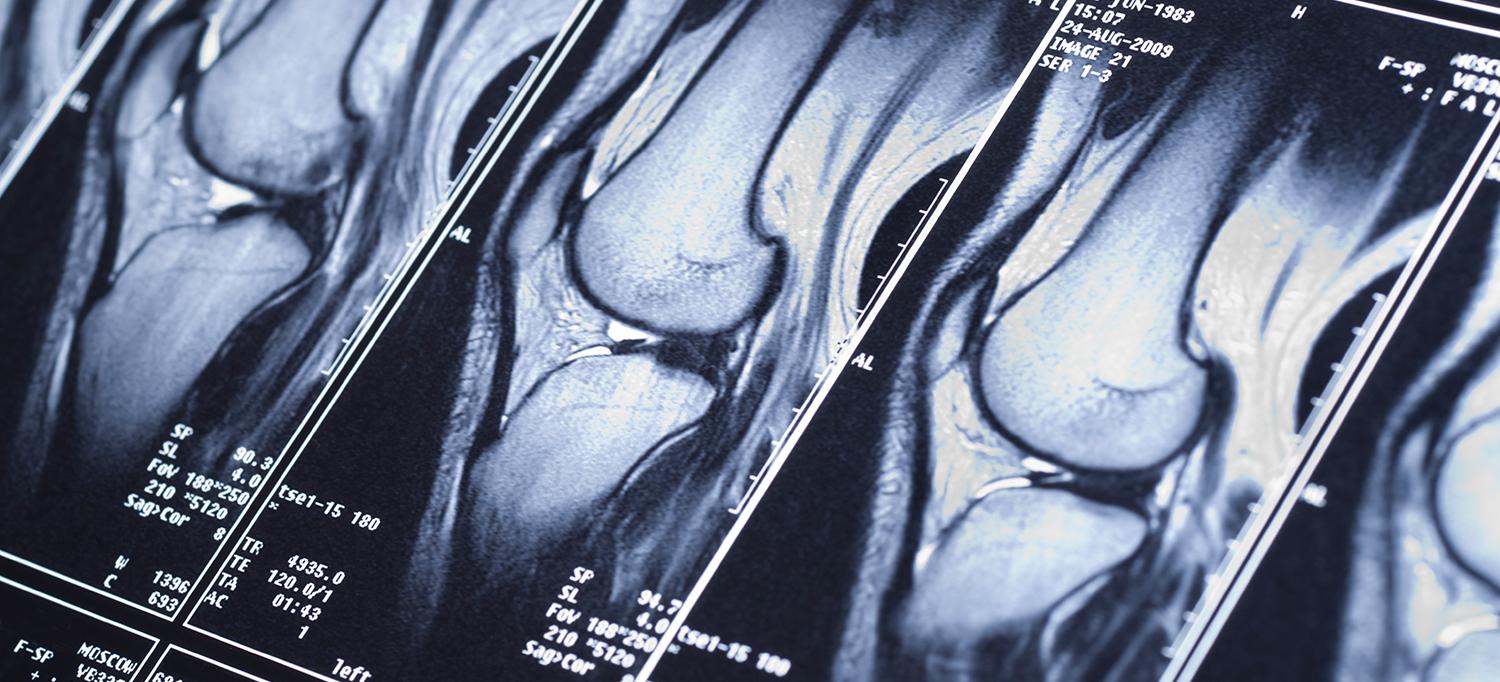
AAPM/COMP, 2020 (Oral Presentation) video Reconstructing detail rich MRI using prior information from multi-imaging protocols and spatial non-local MR image patch regularities. |
|
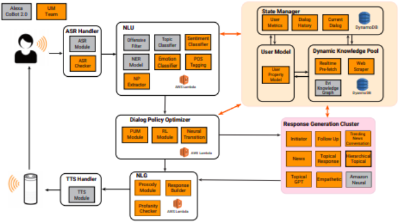
The Alexa Prize Proceedings, 2020 An open-domain conversational chat-bot that aims to engage users on various conversational levels with socially-aware models such as Emotion Detection. |

|
International Conference on Innovative Computing, Information and Control, 2017 A study of changes in attention and episodic memory of human participants due to Human-Robot social interactions. |
|
|
|
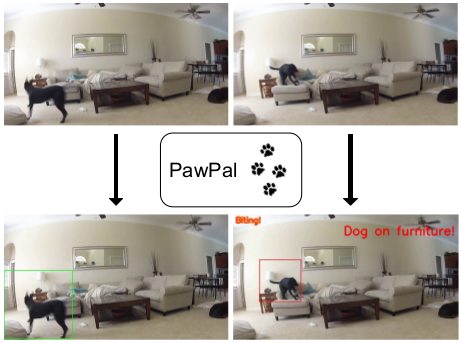
PawPal
EECS 504: Foundations of Computer Vision Instructor: Dr. Jason Corso poster / code / report Using state-of-the-art computer vision algorithms, we developed a dog localization and activity recognition system that can determine what your dog is doing from a home surveillance camera. An innovative solution allowing autonomous active monitoring and safekeeping of pets without requiring any interference from the owner. |
|
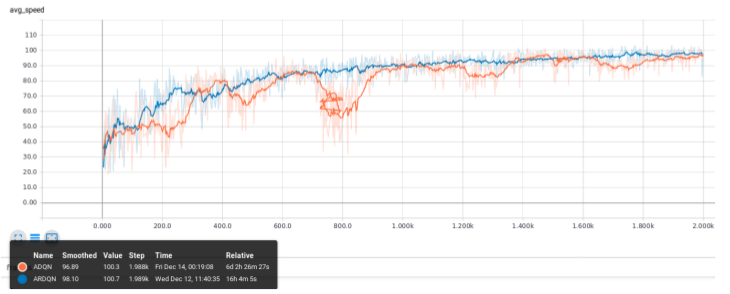
Improving Traffic Flow with Deep RL
EECS 545: Machine Learning Instructor: Clayton Scott code / report We compared Action-specific Deep Q networks (ADQN) and Action specific Recurrent Deep Q networks (ADRQN) to drive vehicles in the Deep Traffic Simulator. The recurrent network can handle partial observability induced by only having access to a partial field of view per timestep and converges faster in this setting. |
 
|
3D Visual Scene Understanding
Independent Study Instructor: David Fouhey I implemented a ResNet-DenseNet encoder-decoder network for estimating depth maps, normals and occlusion edges from single images on the NYUv2 dataset . The hope was to exploit learnt feature representations and intra task dependencies for efficient transfer learning. |
|
Gluttonous: A greedy Algorithm for Steiner Forest
EECS 598: Approximation Algorithms Instructor: Viswanath Nagarajan presentation / report / original arxiv paper We summarized the core ideas behind Greedy Algorithms for solving Steiner Forest problems in a short technical report and presented the intuition behind these algorithms in an easily understandable and comprehensive presentation. |
|
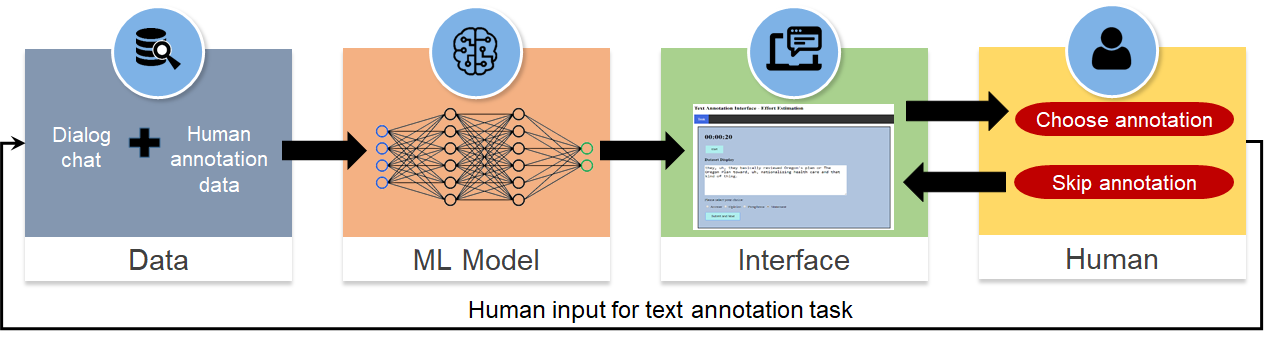
Lazy Human AI Teams
EECS 598: Human-AI Interaction and Crowdsourcing Instructor: Walter S. Lasecki code / report We explored the use of Human Effort as an additional task dimension in Human-AI teams and showed that optimising Human Effort in an active learning paradigm improves overall team performance. I simulated a variety of active learning experiments on the Swicthboard corpus and designed a simple web interface to conduct experiments. |
|
Generalizing Navigation Behaviors with Policy Sketches
Independent Study Instructor: David Fouhey proposed abstract We explored long range 3D Navigation in the virtual House 3D environment. I defined behavioral primitives important for navigation at large scales and implemented Imitation Learning to learn these primitives as policy sketches through supervised demonstrations. The goal was to learn a general navigation policy as a sequence of such policy sketches. |

|
VAE for Painting Timeline
CS 771A: Introduction to Machine Learning Instructor: Purushottam Kar report The current architecture of VAE suffers from latent space saturation (with inefficient packing) and mode collapse. We aimed to deal with mode collapse by introducing more than one encoder in the architecture, with the latent spaces mapped to a single decoder. We attempted to incorporate different techniques to get good reconstructions. |
|
|
 |
SI 301: Models of Social Information Processing - Instructional Aide |
|
|